2023-02
LLM-Enhanced Customer Data Matching
Automating record reconciliation with AI-powered precision
Overview
When two databases describe the same customer differently — one says "ABC Security LLC", another says "A.B.C. Security, Lancaster" — traditional exact-match queries fail. This project built a multi-layered matching system that uses fuzzy string algorithms as a first pass and Llama 3.2 as the intelligent decision layer, producing confident match/no-match decisions with explicit reasoning.
The system reconciles customer accounts across two internal databases, handling name variations, address formatting differences, and subsidiary relationships that no rule-based system could manage reliably.
Architecture
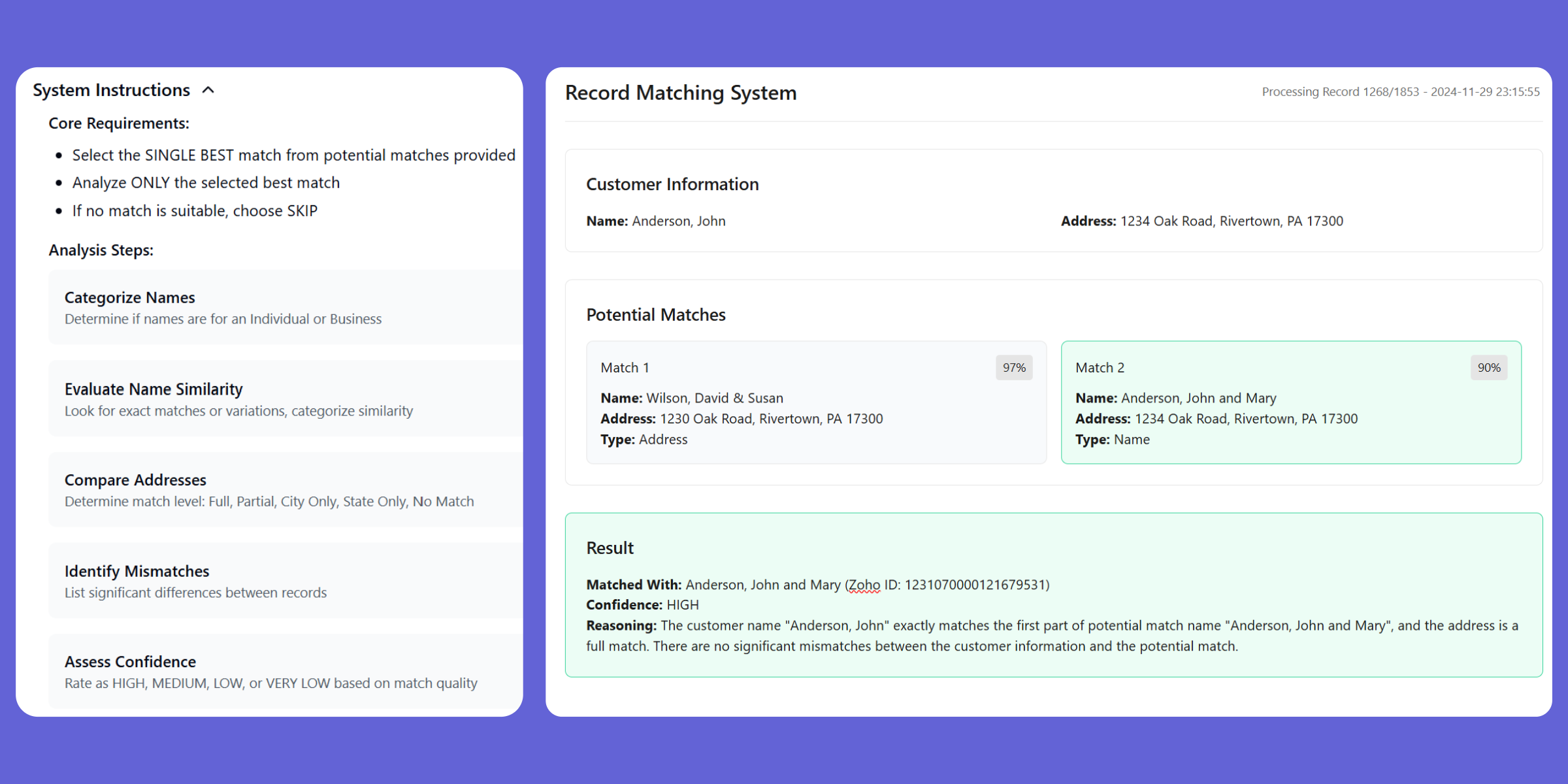
Layer 1: Fuzzy Pre-filtering
Before involving the LLM, I normalize and fuzzy-match company names and addresses to generate candidate pairs. This narrows the search space and avoids burning LLM calls on obvious non-matches.
from rapidfuzz import fuzz
def normalize(name: str) -> str:
name = name.lower().strip()
# Remove legal suffixes that vary between systems
for suffix in ["llc", "inc", "corp", "co.", "ltd"]:
name = name.replace(suffix, "").strip()
return re.sub(r"[^a-z0-9\s]", "", name)
def get_candidates(record, pool, threshold=65):
normalized_target = normalize(record["name"])
return [
candidate for candidate in pool
if fuzz.token_sort_ratio(
normalized_target, normalize(candidate["name"])
) >= threshold
]Layer 2: LLM Decision Engine
Each candidate pair gets evaluated by Llama 3.2 using a structured prompt that enforces a seven-step analysis sequence. The prompt is engineered to prevent two common LLM failure modes: overconfident matching on superficial similarity, and decision paralysis on ambiguous cases.
MATCH_PROMPT = """
Analyze whether these two records represent the same business.
Record A: {record_a}
Record B: {record_b}
Follow these steps in order:
1. Compare normalized business names and note similarity patterns
2. Evaluate address match (exact / partial / different city / no address)
3. Check for known subsidiary or DBA relationships
4. Assess phone/contact overlap if present
5. Consider whether name differences suggest rebranding vs. different entity
6. Assign a confidence level: HIGH (>90%), MEDIUM (70-90%), LOW (<70%)
7. Make a final MATCH or NO_MATCH decision
Constraints:
- Analyze only the pair provided — do not reference other records
- A HIGH confidence MATCH requires agreement on at least name + address
- If confidence is LOW, default to NO_MATCH
- Explain your reasoning before the final decision
Output format:
DECISION: [MATCH|NO_MATCH]
CONFIDENCE: [HIGH|MEDIUM|LOW]
REASONING: [your analysis]
"""Layer 3: Post-processing and Validation
LLM output is parsed with regex against the enforced format. Results below a configurable confidence threshold are flagged for human review rather than auto-applied.
Key Design Decisions
Conservative defaults. When in doubt, the system returns NO_MATCH. A false positive (merging two real customers) is far more damaging than a false negative that leaves one account unmatched.
Structured response format. Forcing DECISION: / CONFIDENCE: / REASONING: labels makes parsing reliable and creates an audit trail — you can always explain why any match was made.
Separating concerns. Fuzzy matching is cheap; LLM calls are not. Keeping them as distinct layers means the LLM budget goes only toward genuinely ambiguous pairs.
Outcome
The system processed the full customer database backlog in an overnight batch run. Match quality was validated against a hand-curated test set: precision above 94%, with no false positives in the HIGH confidence bucket.
Manual reconciliation that previously took weeks per quarter now runs automatically as new accounts are created.